Are you intrigued by the advancements in generative AI models and interested in evaluating their performance? Look no further! In this article, we will delve into the key metrics, challenges, and opportunities associated with evaluating generative AI models. As AI continues to revolutionize various industries, understanding how to assess generative AI models becomes paramount.
However, evaluating generative AI models also comes with its fair share of challenges. From overfitting to understanding the limitations of metrics, we will navigate through the hurdles that may arise during evaluation. Moreover, we will discuss the opportunities that emerge when it comes to expanding the current evaluation approaches and techniques. Stay tuned as we uncover the ins and outs of evaluating generative AI models.
Importance of Evaluating Generative AI Models
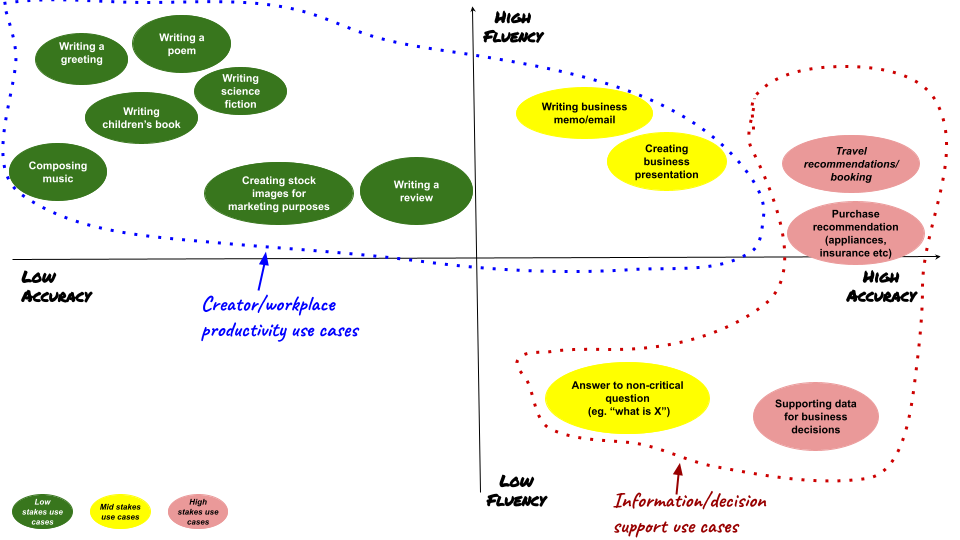
Evaluating generative AI models is crucial for several reasons, primarily revolving around trust and reliability. As these models are increasingly deployed in real-world applications such as content generation, art creation, and even decision-making, stakeholders need to ensure that they perform effectively and without unintended consequences. By establishing robust evaluation frameworks, developers can ascertain that their models generate high-quality outputs consistently, thus enhancing user confidence. This trust is particularly important in industries like healthcare, finance, and law where the stakes are significantly higher.
Moreover, evaluating generative AI models allows researchers and developers to identify the strengths and weaknesses of their models. Understanding performance metrics not only aids in improving existing models but also fosters innovation by highlighting areas that require further research. For instance, if a particular model consistently fails to generate coherent text, it may lead to investigations into new architectures or training datasets. This iterative process of evaluation and improvement is essential for advancing the field of generative AI and ensuring that models meet user expectations.
Key Metrics for Evaluating Generative AI Models
When it comes to evaluating generative AI models, several key metrics are commonly employed to quantify their performance.
Perplexity: It measures how well a probability distribution predicts a sample. Lower perplexity values indicate that the model can generate text that closely resembles actual human language, making it a valuable metric for language generation models. By calculating perplexity on a validation dataset, developers can assess how well their model generalizes beyond the training data.
BLEU (Bilingual Evaluation Understudy): It is primarily used in the evaluation of machine translation but also applicable to generative text models. BLEU scores range from 0 to 1, with higher scores indicating better performance. This metric compares the generated output to one or more reference outputs, measuring the degree of overlap in n-grams. While BLEU is effective in assessing the adequacy of generated text, it has limitations.
ROUGE: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) focuses on recall, measuring the overlap of n-grams between generated and reference texts.
METEOR: METEOR (Metric for Evaluation of Translation with Explicit ORdering) incorporates synonymy and stemming. These combined metrics provide a more holistic view of a model’s performance, allowing for better comparisons across different systems and applications.
Challenges in Evaluating Generative AI Models
While evaluating generative AI training models is essential, it comes with its own set of challenges.
Inherent subjectivity involved in determining the quality of generated outputs. Human evaluators may have differing opinions on what constitutes good quality text, leading to inconsistent results. This subjectivity can be exacerbated in creative applications, such as poetry or art generation, where personal taste plays a significant role. Developing standardized evaluation frameworks that incorporate human judgment while minimizing bias is a crucial challenge for researchers.
Overfitting means a model performs well on training data but fails to generalize to unseen data. Evaluating models solely based on training metrics can provide a misleading sense of performance. It is essential to use diverse validation datasets that reflect real-world applications to ensure models are robust and can maintain quality across various contexts. This often requires careful dataset curation and an understanding of domain-specific requirements, which can be resource-intensive.
Opportunities for Improving Evaluation of Generative AI Models
Despite the challenges, there are numerous opportunities to enhance the evaluation of generative AI models.
User Feedback: By collecting real-time feedback from users interacting with AI-generated content, developers can gain valuable insights into the effectiveness of their models. This approach fosters a more user-centered design philosophy, aligning the models more closely with user needs and preferences.
Evaluation Techniques: By generating challenging inputs that are specifically designed to confuse or mislead models, researchers can gain deeper insights into their limitations. This can lead to the development of more robust models capable of handling edge cases, thereby improving overall performance.
Interdisciplinary Collaboration: It presents a significant opportunity for enhancing evaluation frameworks. By drawing insights from fields such as psychology, linguistics, and ethics, AI researchers can develop more comprehensive evaluation strategies that account for the nuances of human communication and societal impact.
Case Studies of Successful Evaluation Methods
Several case studies illustrate successful evaluation methods for generative AI models, showcasing innovative approaches that have yielded valuable insights.
OpenAI’s Evaluation
The team employed a combination of automated metrics like perplexity and human evaluations to assess the quality of outputs across various tasks. This multifaceted evaluation strategy allowed them to identify strengths in the model’s ability to generate coherent and contextually relevant text while also highlighting areas needing improvement, such as factual accuracy.
Google DeepMind’s
By implementing a panel of expert musicians alongside computational metrics, the team was able to assess the creative quality of the generated compositions effectively. This hybrid evaluation model ensured that human artistic standards were integrated into the evaluation process. As a result, their generative music models achieved high levels of creativity and engagement.
NVIDIA Image Generation Models
By utilizing both quantitative metrics, such as Inception Score and FID (Fréchet Inception Distance), and qualitative assessments from human judges, they could comprehensively evaluate the visual fidelity and diversity of generated images. This dual approach facilitated robust comparisons between different generative models, guiding further advancements in image synthesis technology.
Best Practices for Evaluating Generative AI Models
To ensure effective evaluation of generative AI models, several best practices can be adopted by researchers and developers.
Set Clear Evaluation Objectives
- Define specific goals based on the model’s intended application.
- Identify what constitutes success to tailor evaluation metrics accordingly.
- Align evaluation processes with the goals to gain meaningful insights.
- Developers with certifications like a MIT AI certificate are well-equipped to set precise evaluation standards based on best practices.
Use a Combination of Metrics
- Utilize both quantitative and qualitative metrics for a balanced assessment.
- Quantitative metrics, such as BLEU and ROUGE, measure performance objectively.
- Qualitative assessments, like human evaluations, provide deeper insights into the creativity and quality of generated outputs.
- Engage diverse evaluators to reduce bias and consider various perspectives.
Continuous Monitoring and Iterative Evaluation
- Regularly monitor model performance to identify shifts or emerging issues.
- Implement a feedback loop by collecting and incorporating user input.
- Adapt models to meet changing needs, fostering continuous improvement.
Tools and Resources for Evaluating Generative AI Models
A variety of tools and resources are available to assist researchers and developers in evaluating generative AI models effectively.
Popular AI Libraries
- TensorFlow and PyTorch offer built-in functions for calculating common evaluation metrics such as BLEU and ROUGE.
- These libraries provide a user-friendly interface for implementing evaluation protocols, enabling developers to focus on model performance.
Specialized Frameworks
- NLTK (Natural Language Toolkit) library includes modules for assessing text generation quality. These dedicated benchmarks like GLUE provide standardized datasets for evaluating language models.
- These frameworks can streamline the evaluation process, allowing for comparisons across different models and facilitating the identification of best practices.
Collaborative Platforms
- Hugging Face and Papers with Code have emerged as valuable resources for sharing evaluation methodologies and results.
- Engaging with these communities can provide insights into emerging trends and foster knowledge sharing.
Future Trends in Evaluating Generative AI Models
As the field of generative AI continues to evolve, several future trends are likely to shape the evaluation landscape. One significant trend is the increasing focus on transparency and explainability in AI models. As stakeholders demand more accountability from AI systems, evaluation frameworks will need to incorporate metrics that assess not only performance but also the interpretability of generated outputs. This shift will encourage the development of models that can provide explanations for their decisions, fostering greater trust among users.
Another trend is the growing importance of ethical considerations in evaluation processes. As generative AI models are deployed in diverse and sensitive applications, the need to evaluate for biases and ethical implications will become paramount. Developers will be challenged to create metrics that go beyond conventional performance measures and assess the societal impact of their models. This may involve developing new evaluation frameworks that prioritize fairness, inclusivity, and social responsibility.
Conclusion
Evaluating generative AI models is a complex yet essential endeavor that influences the future of artificial intelligence. By understanding the importance of evaluation, employing key metrics, and navigating the associated challenges, researchers and developers can enhance their models’ effectiveness and reliability. The opportunities for improving evaluation methods, illustrated through successful case studies and best practices, highlight the potential for innovation in this field.
As the landscape of generative AI continues to evolve, embracing emerging trends and utilizing available tools will be crucial for driving advancements in model evaluation. By prioritizing transparency, ethical considerations, and real-time feedback, the AI community can work towards developing models that not only perform well but also align with societal values. Ultimately, robust evaluation frameworks will empower stakeholders to harness the full potential of generative AI while addressing the challenges that lie ahead.